in English
Alle snakker om Machine Learning i 2017. Hos eCapacity tager vi skridtet videre – fra snak til handling, og fra buzzwords til business.
Læs eventuelt denne case, hvor eCapacity med AI (kunstig intelligens) kunne hjælpe Codan med at forudse og personalisere deres startside for hver unikke bruger. Startsiden blev udvalgt blandt 60 mulige, hvilket resulterede i at konverteringsraten steg markant.

Vi er altid på udkig efter inspiration til hvordan Machine Learning kan forvandle data til forretningsværdi.
I sidste uge var vi i Stockholm for at deltage til Google Cloud Summit, hvor omdrejningspunktet var AI og Machine Learning. Her er fem inspirerende cases.
1. MQT: Forudser værdifulde startup investeringer

MQT kombinerer enorme mængder af digitale fodspor, computerkraft og Machine Learning for at forudsige hvilke startup virksomheder, der vil blive økonomiske succeser. 15.000 virksomheder bliver stiftet hver dag, så hvordan ved du hvilke man bør satse på?

MQT bruger Machine Learning og ’menneskelig dømmekraft’ til at identificere typiske mønstre og karakteristika for succesfulde startup virksomheder, så MQT kan investere i dem før alle andre.

2. Aker BP – Forudsigelse af vedligeholdelsesopgaver på en boreplatform

Olieindustrien mister markedsandele og bliver nødt til at blive effektiviseret for at overleve.
Akter BP har over 100.000 sensorer på deres nye boreplatform, Ivar Aasen, og de bruger Machine Learning til at finde mønstre i data på tværs af 50 forskellige applikationer.
Service af en trykluftpumpe (turbine) kan koste op til 30 millioner EUR. Ved at benytte Machine Learning til at forudse overbelastninger, kan serviceomkostningerne reduceres kraftigt ved, at service kun er nødvendigt hvert 6 år i stedet for hvert 3 år.
3. Deli Ice Cream: Optimering af is-udbringning i Singapores trafikhelvede

Google brugte den fiktive virksomhed, Deli Ice Cream, til at demonstrere hvad Machine Learning er i stand til i samspil med Google Maps.
Deli Ice Cream benytter cykler til at levere is i hjertet af Singapore. Cyklerne er udstyret med en lille fryser for at holde isene kolde, men det kan fryseren kun i begrænset tid.
Derfor benytter Deli Ice Cream sig af Google Map’s API til at optimere leveringsruterne.
Systemet kombinerer: lokationen, antal is på cyklen og trafiksituationen med Machine Learning for at forudse hvilken cykel der kan nå hen til kunden hurtigst muligt. Den hurtigste rute bliver sendt til cyklen og den estimerede leveringstid bliver sendt til kunden.
4. Instant Insights: Real-time forudsigelse af relevante reklamer for taxakunder
En anden af Google’s fiktive Machine Learning demoer var Instant Insights.
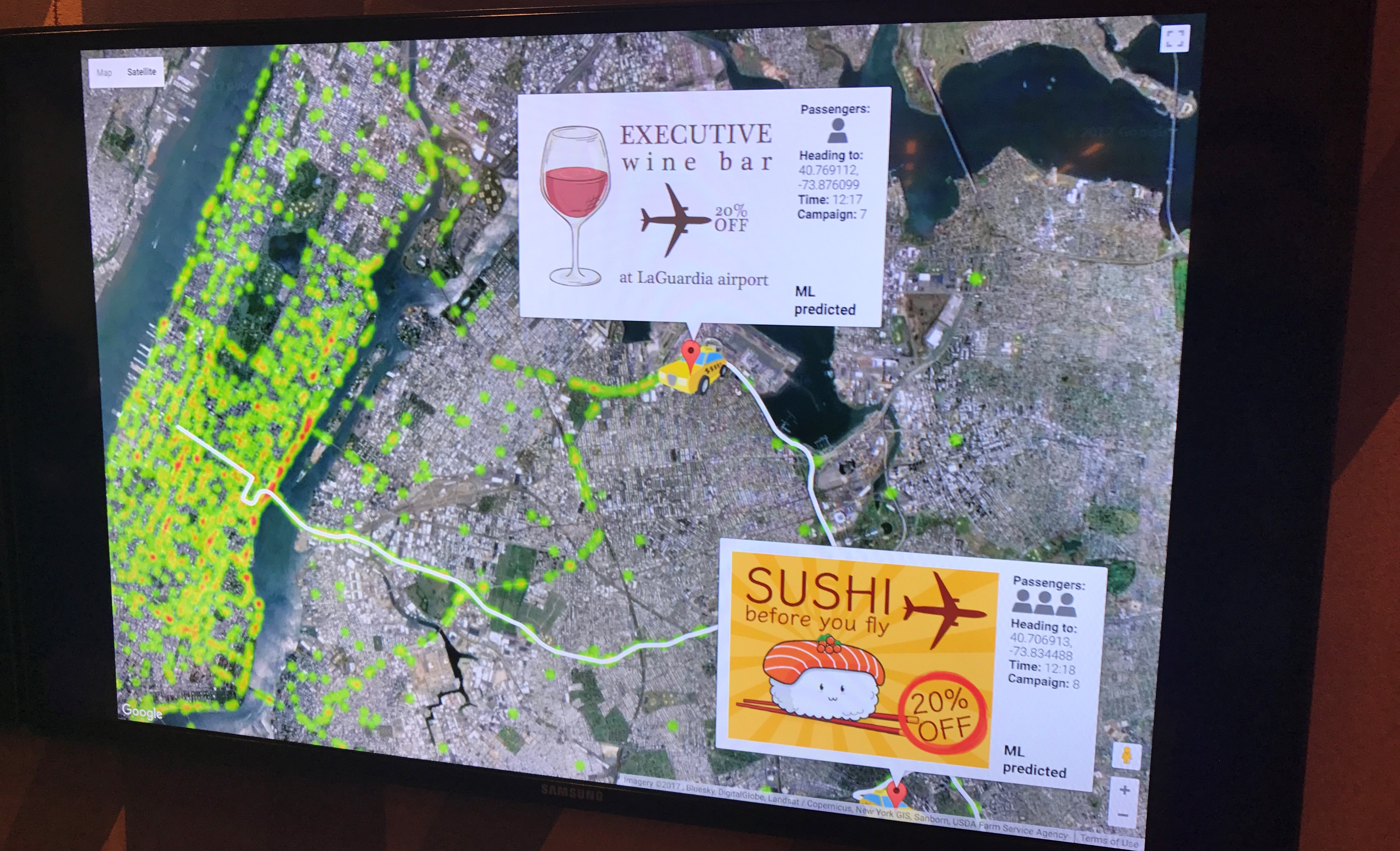
Ved at benytte Machine Learning og real-time data fra taxaer, såsom: rejsens udgangspunkt, antal passagerer, tid på dagen og estimerede taxarute, kan taxaer vise passageren relevante reklamer for spisesteder og butikker nær taxaens slutdestination.

Passageren kan klikke på reklamerne for at få mere information og systemet kan så fremover bruge, ’reinforcement learning’ til at finde ud af hvilke reklamer der er mest relevante for passagerne.
4a. Spotify – Real-time streaming indsigt til kunstnere.
Okay, den her handler ikke om Machine Learning, men casen inkluderer en masse data, hvilket altid får os til at dreje hovederne. Desuden lyder 5 i overskriften bedre end 6, ik?
Vi siger ikke nødvendigvis, at Spotify har enorme mængder af data – men det er ikke mange virksomheder, som har et Hadoop cluster med 2500 noder.

For hurtigere at kunne opnå indsigter fra dataene, har Spotify skiftet fra deres Hadoop cluster til en Google BigQuery løsning, hvilket giver hurtige indsigter til deres 740 aktive brugere af BigQuery (det er 25% af medarbejderne på Spotify). Dertil giver det kunstnere på Spotify adgang til real-time statistikker over afspilninger af deres udgivelser.
Okay, vil du have den femte case om Machine Learning?
Værsågod: 5. Google Search
For næsten 9 år siden begyndte Google Search at bevæge sig væk fra menneskeskabte regler til computerskabte regler, ved at definere hvordan gode søgeresultater bør se ud og så lade en computer finde ud af hvad resultaterne skal være.

Google havde mere end 3 millioner menneskeskabte regler til at finde ud af de mest relevante søgeresultater for forespørgsler, som eksempelvis ”Giants”, som afhang af om brugerens lokation var eksempelvis New York eller San Francisco.
3 millioner menneskeskabte regler!
Ved at erstatte de regler med karakteristika for gode søgeresultater, som eksempelvis resultater med høj click-through-rate, kigger maskinen på brugerens lokation og andre relevante informationer om brugeren, for at teste reglerne og forbedre søgeresultaterne automatisk.
in English